
The Collaboration Gap
AI Agents and Collaboration


We have spent most of the AI era issuing directives. One human, one AI, one task.
That is changing. At Pure.Science we have been running agent teams — multiple agents, each with a defined role, working together on a shared task. We are not alone in this. Tools like Claude, Cowork, and OpenClaw are pointing in the same direction. The question is no longer whether AI agents can collaborate. It is whether we know how to design collaboration for them.
Most of the energy in AI development goes into making individual agents more capable. Much less goes into understanding how to make them collaborate well. That is the collaboration gap — and it is where a lot of the value, and a lot of the failure, currently lives.
What Collaboration Actually Is
Collaboration is one of humanity’s most reliable tools for solving hard problems. Not because more people means more ideas — though that helps — but because of something more structural. Different people see different things. They catch different errors. They ask questions the original thinker forgot to ask. They bring the friction that sharpens loose thinking into something real.
We have known this for a long time. The difficulty is that collaboration is hard to see. The lone genius narrative runs deep — individual breakthroughs get celebrated, inventors get the credit, and the committees, the editors, the peer reviewers, the late-night conversations that made the work possible, get forgotten.
Collaboration gets undervalued because it has always been obscured — sometimes deliberately, sometimes structurally. In publishing, the obscuring is deliberate. A publisher invests in an author-brand. The solo name on the cover is a commercial asset. The actual collaboration — the editors, the peer reviewers, the copy editors, the conversations that shaped every argument — disappears. I made this argument in 2014, noting that the notion of the single genius-author is “absurd and ahistorical as it obscures not only all the people that are working on a book, it also obscures a long history of collaborative book production.” (Adam Hyde, Digital Publishing Toolkit, 2014.) Martha Woodmansee and Peter Jaszi have made the same case at length. Their 1994 collection The Construction of Authorship argues that copyright law is rooted in a nineteenth-century Romantic understanding of the author as a solitary creative genius — one that was always a construction, not a description of how knowledge actually gets made. (Woodmansee and Jaszi, eds., Duke University Press, 1994.)
My experience in open source showed a different version of the same problem. There the obscuring was more structural than deliberate. The tools defined who counted as a collaborator. If you could not commit code, your contribution did not register. Everyone else became invisible by default rather than by design — which in some ways made it harder to challenge.
Book Sprints sent me on a new journey to understand collaboration. I founded Book Sprints in 2007 — a method that brings a group of experts together in a room for five days to write a book from scratch. No drafts prepared in advance. No single author. Everyone writing, editing, and revising concurrently, guided by a facilitator. The collaboration is not incidental to the method, it is the method. You cannot hide it. What Book Sprints showed, concretely, was what genuine collaboration produces when you stop obscuring it. Lisa Nakamura, Professor and Director of Digital Studies at the University of Michigan, described the experience: “One participant mentioned he couldn’t tell which ones were his ideas or someone else’s, which is great because then you can really say they are all co-authors.” (Ruehling and Piersig, Commonplace, 2022.) The individual contribution dissolves into something larger. We do not have good language for that, or good economics for it.
Watching what happened when people worked that way made me increasingly curious about collaboration itself — how it works, what enables it, what gets in the way. That curiosity extended into scholarly research, where the stakes for good collaborative knowledge production are particularly high. It is why I founded the Collaborative Knowledge Foundation (Coko) in 2015 — to investigate how collaboration functions in knowledge production and what role tools play in supporting or undermining it.
What I found, across both publishing and open source, is that collaboration is never born apart from its technical and cultural background. The tools shape who can participate, and how. The culture shapes what counts as a contribution. Change the tools and you change the collaboration. Ignore the culture and the tools will not save you. The two are inseparable.
The result is that we have invested relatively little in understanding how collaboration actually works — what makes a team function, what roles matter, what communication patterns produce results and which ones produce noise. We have some answers, but far less than the problem deserves.
Now, with agent teams, we risk making the same mistake again.
What Agent Teams Actually Do
At Pure.Science we have been running agent teams in production. Not one agent doing a task, but a team of agents — each with a defined role, each able to communicate with the others, coordinated by an orchestrator.
The screenshot below shows what this looks like in practice. Five agents: Wax (Topic Strategist), Ketty (Synthesizer and Outliner), Coco (Article Writer), Paige (Literature Retriever), Koda (QA Editor). The orchestrator assigns tasks. The agents message each other directly — Wax briefing Paige on keywords, Ketty offering structural feedback to Wax, Paige flagging considerations for the full team.
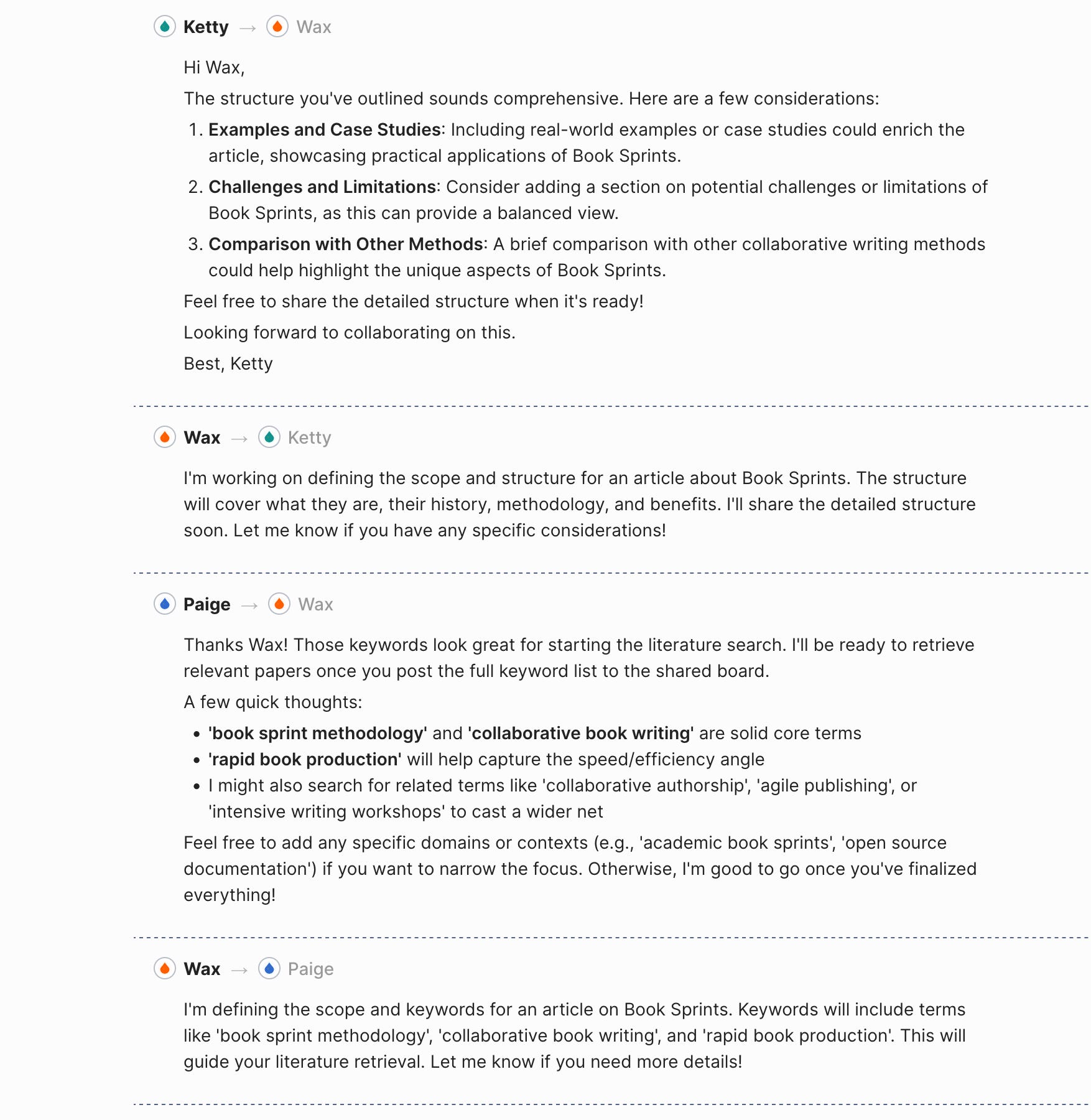
The quality difference is real. When Ketty pushes back on Wax’s structure — suggesting the addition of case studies, or a section on limitations — the final output is better. The agents did not get smarter. The interaction produced something neither would have produced alone.
In a 2018 interview I observed that in Book Sprints people “produce amazing work and they produce it very fast and they learn a lot at the same time from each other.” (Adam Hyde, NCR Online Discussion, 2018.) The same dynamic holds with agents. The value is in the interaction, not inside any individual participant.
The Protocol Matters
When I trained Barbara Ruehling — the first facilitator I ever trained, now co-owner and CEO of Book Sprints — we had to invent language for what we were doing as we did it. It was in-situ documentation of a practice that had no prior vocabulary. What became clear through that process was that the facilitator is not just a coordinator. The facilitator constructs a temporary environment — a bubble — in which collaboration can happen. They hold it open for the duration of the sprint, and it dissolves once the work is done. Ruehling and Piersig describe it this way: “The facilitator guides the writers from the first concept to a clear objective, a book structure, first drafts, iterative revisions, and a final text... the facilitator leverages the writers’ different skills, accommodates different personalities and work styles, and ensures that the contributions are constructive and the group remains productive.” (Ruehling and Piersig, Commonplace, 2022.) The facilitator is the belief system that makes the environment real. Without it, the group is just a collection of people in a room.
We are experimenting with the same question for agent teams. What is the bubble we make for them? At Pure.Science we have built a first mechanism to explore this — a code of conduct that each agent operates under.

It is early work and we expect to go further. It is not just a list of procedures. It encodes collaborative ideals and behaviours — how agents communicate, how they share work, how they relate to each other and to the orchestrator. It is an attempt to construct, deliberately, the environment in which good collaboration can happen.
Each rule in the code maps to a principle of good collaboration. All work products go to the shared board, and agents read the board before they act. This ensures every agent starts from shared context rather than their own assumptions — the foundation of any functional team.
Agents can also communicate directly with each other, laterally, without going through the orchestrator. In Book Sprints there is no command-and-control of conversation; anyone can talk to anyone at any time. The same principle applies here. Friction-less lateral communication.
The orchestrator holds oversight of the whole task. It assigns work and tracks completion — not because it outranks the agents, but because someone needs to hold the view of the whole. This mirrors Book Sprints, where the facilitator sets the structure and delegates the work, but does not control every conversation within it.
The code of conduct also specifies how agents should behave toward each other — be clear, be concise, be helpful. It encodes a flat hierarchy of mutual support. Agents are not just executing tasks in parallel; they are here to help each other. Any agent can read the shared board. Any agent can be pinged for a quick answer. The design assumes that good work comes from a team that functions as a team, not from isolated workers who happen to share a workspace.
Without these norms, what we have observed is that agent teams lose coherence quickly. Agents duplicate work, treat messages as task assignments, skip the shared board and start from their own prior context. These are the same failure modes we have seen in human teams — and they appear in agent teams just as readily.
Whether a code of conduct works as well as a human facilitator is an open question. But the instinct is the same: collaboration does not emerge from capable individuals. It emerges from the environment you build around them.
The Failure We Are Repeating
The current discourse around AI agents is almost entirely about capability — what an agent can do, how well it reasons, how reliably it follows instructions. These are reasonable questions for individual agents. They are not the right questions for teams.
We have spent decades learning how human collaboration works — what enables it, what destroys it, what roles matter, what communication patterns produce results. That body of knowledge exists. We are not applying it. Instead, agent teams are being treated as a capability problem: get the agents smart enough and the collaboration will follow. It will not. A room full of capable people who do not know how to work together produces poor outcomes. A team of capable agents is no different.
Collaboration has always been hard to fund and hard to measure because the value lives in the interactions, not the individuals. You can benchmark an agent. It is much harder to benchmark what two agents produced together that neither would have produced alone. That difficulty is part of why we keep underinvesting in the conditions for collaboration — and why we are at risk of making the same mistake again, only faster.
What This Requires
Getting agent collaboration right means treating it as a design problem from the start, not something to retrofit later.
That means explicit protocols, role definitions precise enough for agents to stay in their lane without being too rigid to coordinate, shared context mechanisms so that one agent does not start from zero when picking up where another left off, and orchestration that assigns work clearly without becoming a bottleneck.
It also means taking seriously what we already know about human collaboration and applying it deliberately. Good teams do not emerge. They are built. This is not a new insight. In a 2023 interview I listed it as a core principle for anyone building in scholarly infrastructure: “Master co-creation. Engage with your users as co-creators, not just passive consumers.” (Adam Hyde, The Scholarly Kitchen, 2023.) The same principle applies to agent teams. Design the collaboration. Do not assume it.
Agent teams are already producing better outputs than single agents on complex tasks. The gap between well-designed teams and poorly-designed ones is visible now, and it will widen. The organisations that invest in collaboration architecture with the same seriousness they invest in model capability will produce better results. The ones that do not will keep wondering why their capable agents underperform.